Rearrangement Planning for General Part Assembly
Yulong Li1 Andy Zeng2 Shuran Song1
1Columbia University 2Google Deepmind
Conference on Robot Learning 2023
General Part Assembly Transformer (GPAT)
We tackle the problem with target segmentation followed by pose estimation. To predict accurate segmentation of the target, a key challenge is to deal with the ambiguities in the target shape due to geometrically equivalent parts (e.g., legs of a table). To infer accurate segmentations, we propose General Part Assembly Transformer (GPAT), a transformer-based model architecture, that processes input shapes in a fine-to-coarse manner, thereby ensuring consistent segmentation results.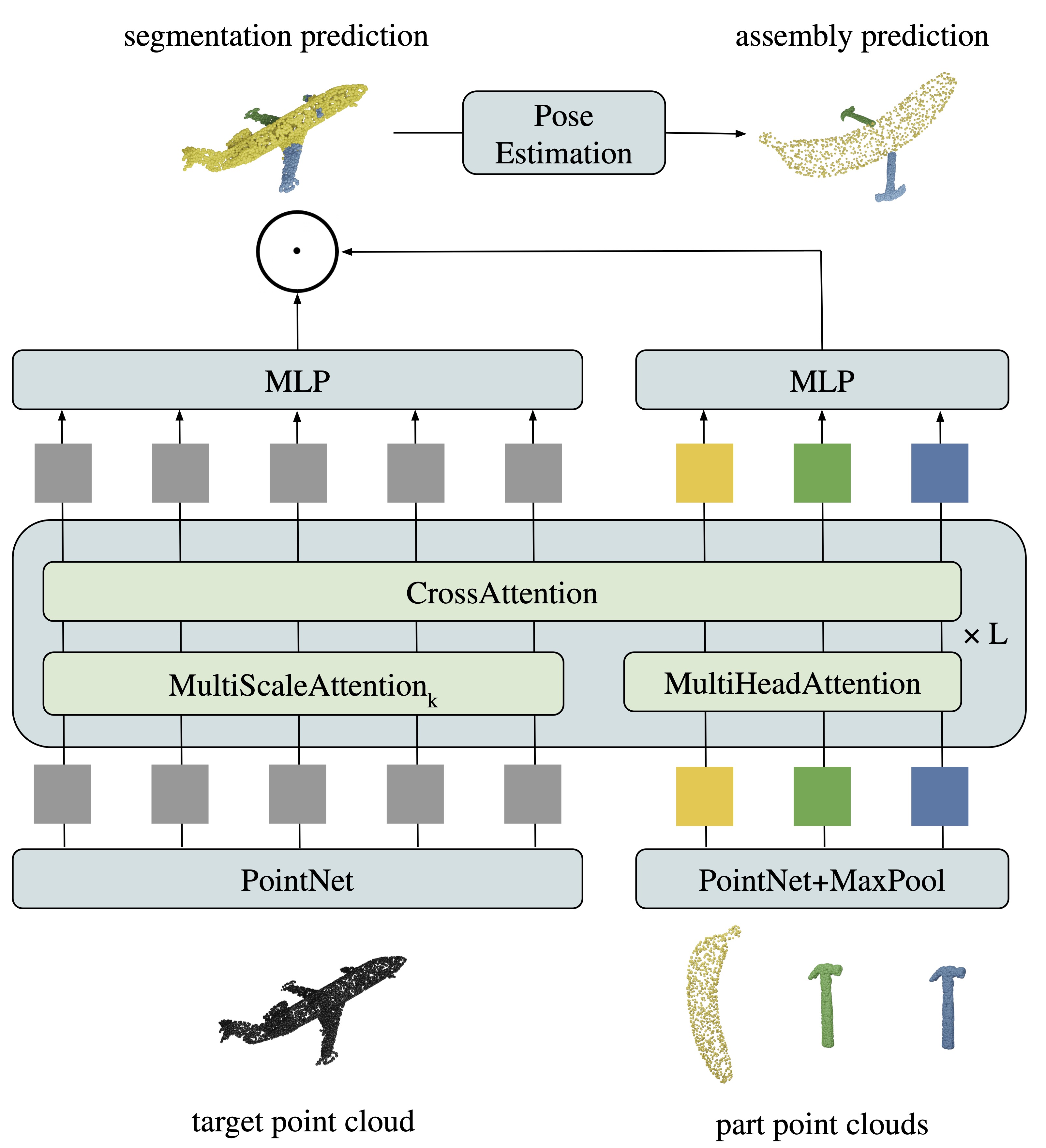
Results
For each test sample, our model takes as inputs a target shape and variable set of part shapes. The target shape may be given at either a caonical pose or a random pose, and part shapes may be exact or non-exact match. Chairs, lamps, and faucets are seen during the training, while tables and displays are unseen categories. The first row of each category displays targets in black, and the second row shows the model predictions.
Results with Real-world Scans as Targets
We use the real-world scans from redwood dataset as targets and part point clouds from the same category of PartNet. As seen in Fig 6, our method produces diverse assemblies that resemble the target given different parts. This result also illustrates how GPAT can be used to assemble different sets of parts given the same target shape.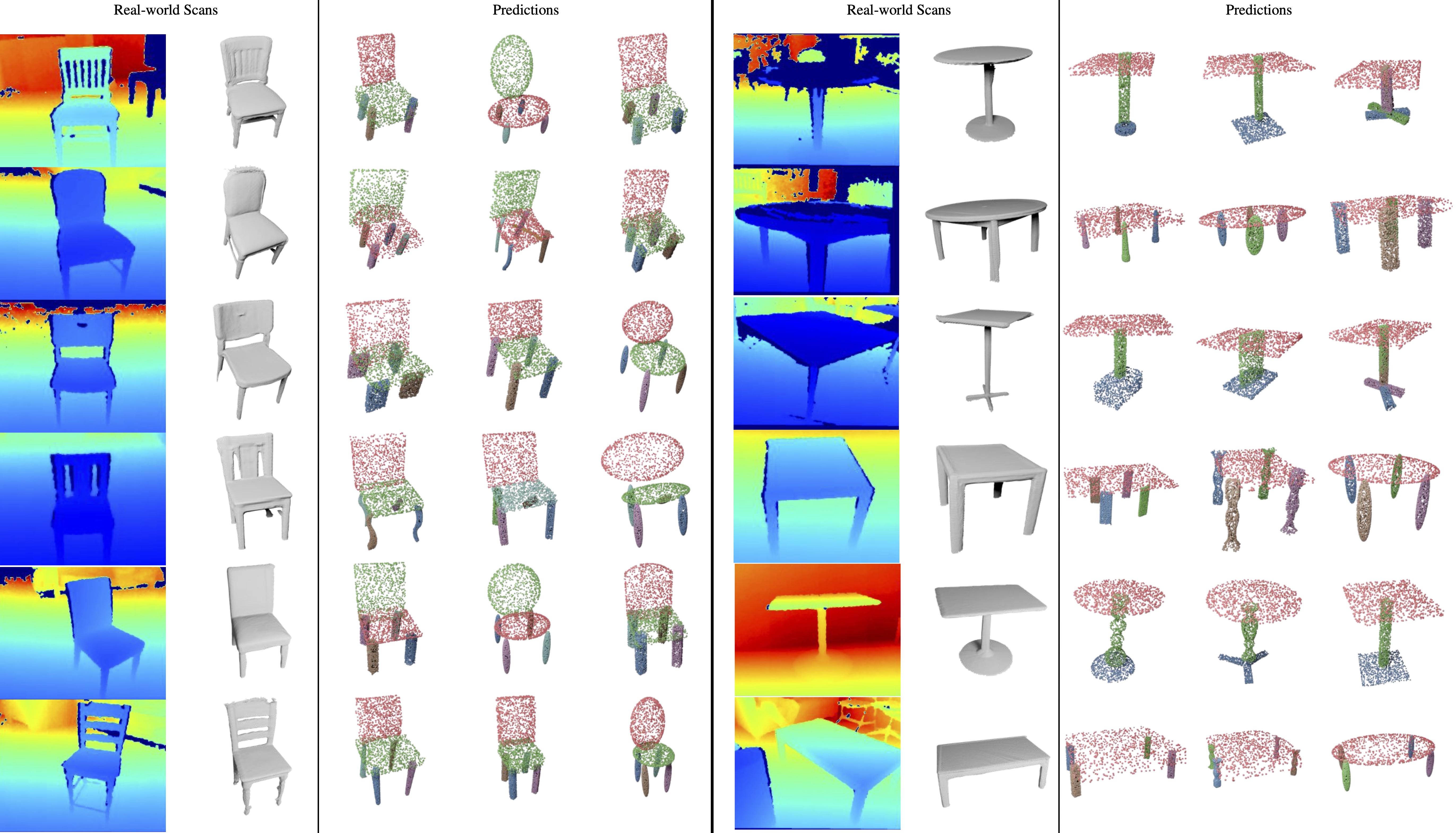
Creative Assemblies
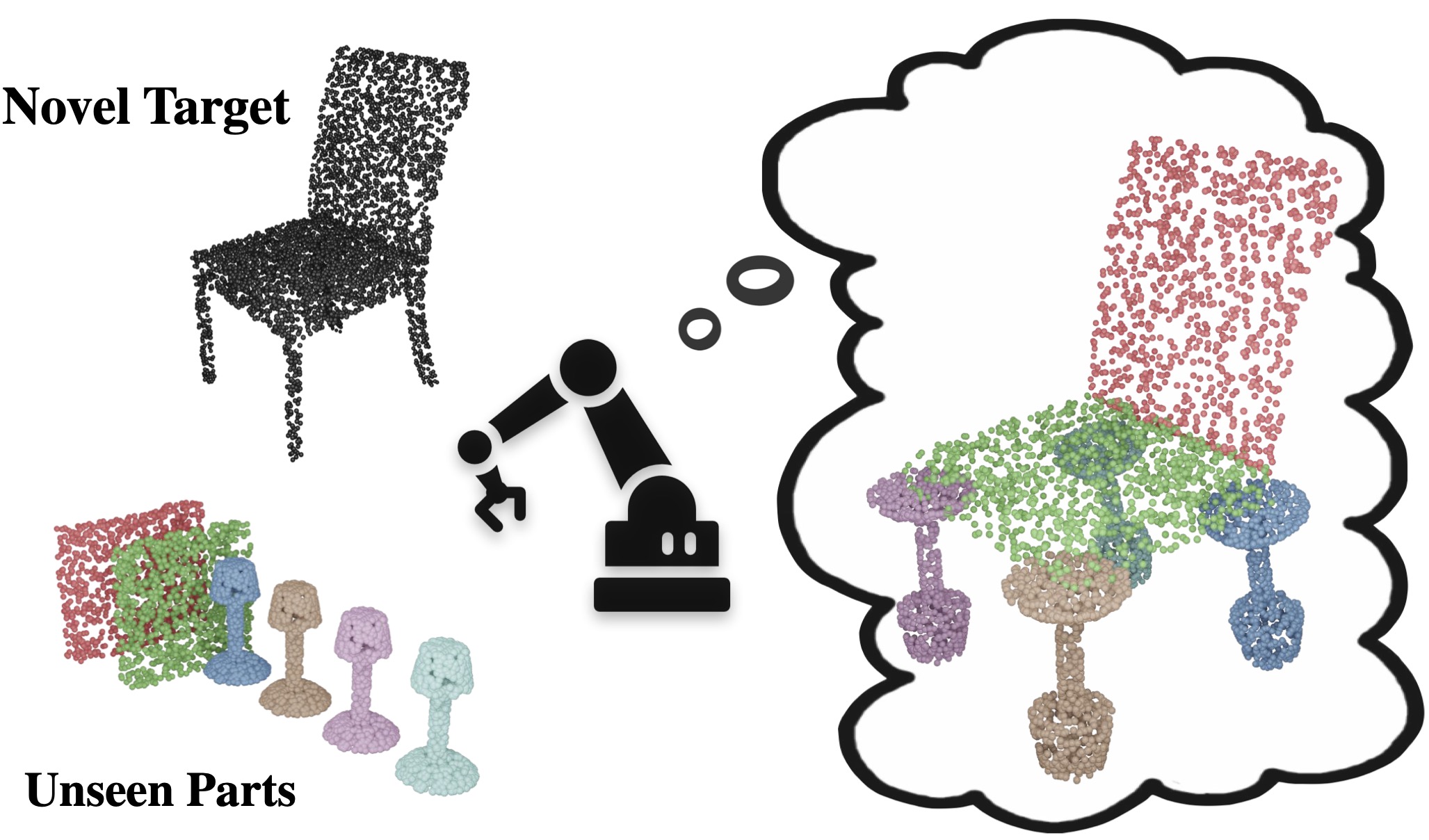
o fully test the generalization abilities of GPAT, we provide unseen part shapes like a banana, hammers, and forks as parts to create novel targets such as a plane. Our model predicts creative assemblies given target shapes from unseen categories and non-exact parts, as seen in Fig. 1.

Multi-scale Attention Layer
TF denotes an alternative segmentation-based model that uses the vanilla transformer, which fails to produce consistent segmentations for targets with geometrically equivalent parts. With the multi-scale attention layer, GPAT fully leverages the spatial structure of the target point clouds to produce consistent segmentations and accurate assemblies.
Optimization is Prone to Local Minima.
As seen in the figure below, directly optimizing the part poses to match the target often result in predictions at local minima where the predicted assembly matches the contour of the target, but the assembly makes no semantic sense.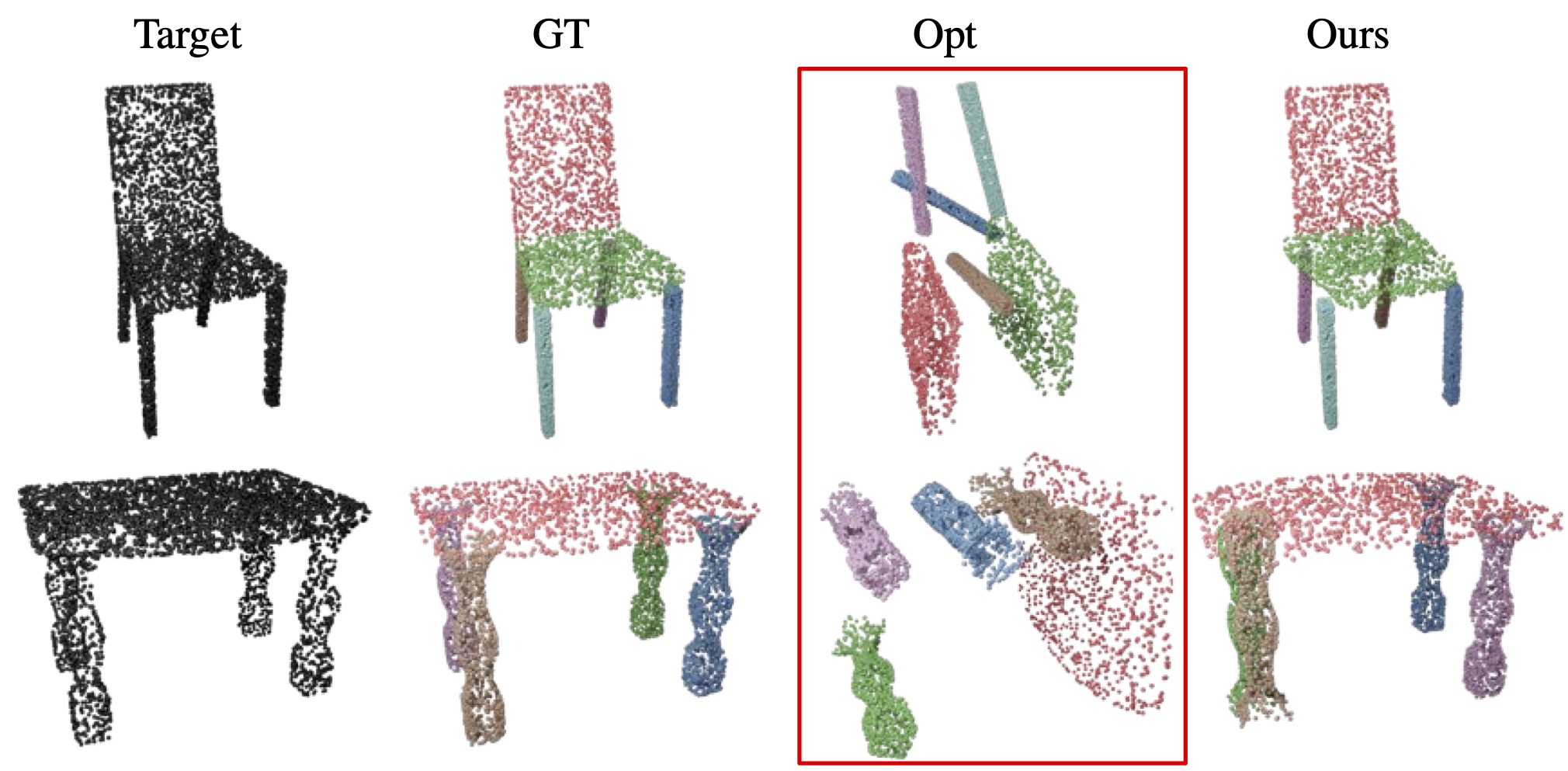
Sensitivity to Scale
Part assembly often involves parts that have the same geometry but different scales, so it is necessary for a model to discriminate parts of different scales to create correct assemblies. As an qualitative illustration in the figure below, we adjust the scale of the parts that have same geometry (the legs of chair/table), and the model correctly associates parts of different scales to the target to build the desired assemblies.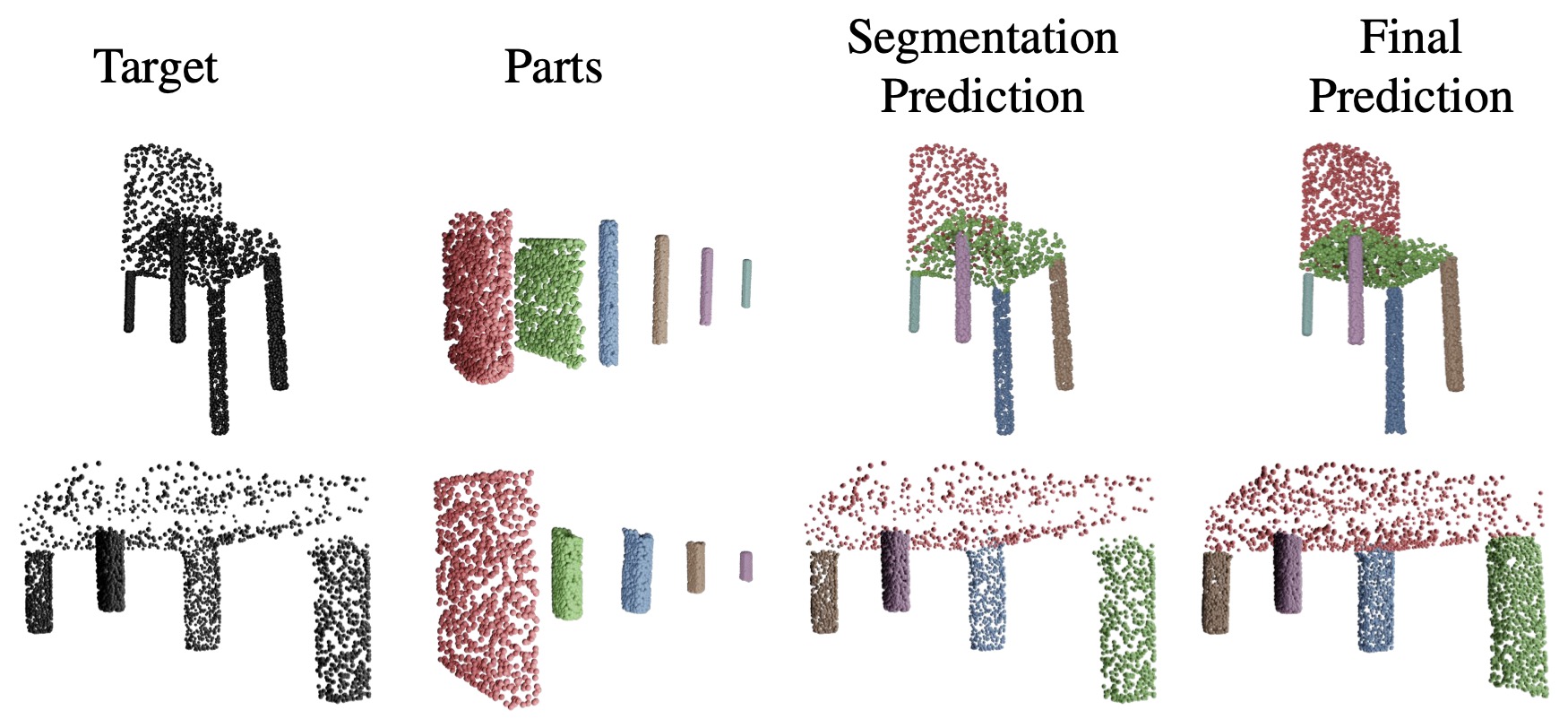
Application to Part Discovery
GPAT is directly applicable to the task of part discovery, \ie, predict a part segmentation given a target, if we do not provide input parts. We show some qualitative results in the figure below to test GPAT's part discovery abilities. Given non-exact parts, PAT predicts accurate segmentations as usual. If we input identical blocks, which specifies the number of parts but provides little information about the part shapes, then GPAT predicts reasonable segmentations with the specified number of segments. Finally, we omit the input parts, and GPAT successfully discovers parts in the target shape.
Failure Modes
GPAT is not without limitations, and the figure below shows some typical failure cases. First, GPAT tends to give incorrect segmentation predictions if some parts are hidden inside a larger part (e.g., the light bulbs in a lamp) or the parts are less separable (e.g., overlapping parts of a microwave). To solve with these issues, it is possible to introduce additional information like colors and normals of the point clouds as inputs. Additionally, oriented bounding box can be insufficient as a pose estimation method for some parts. To tackle this problem, a learning-based pose estimation module can potentially replace the bounding box procedure.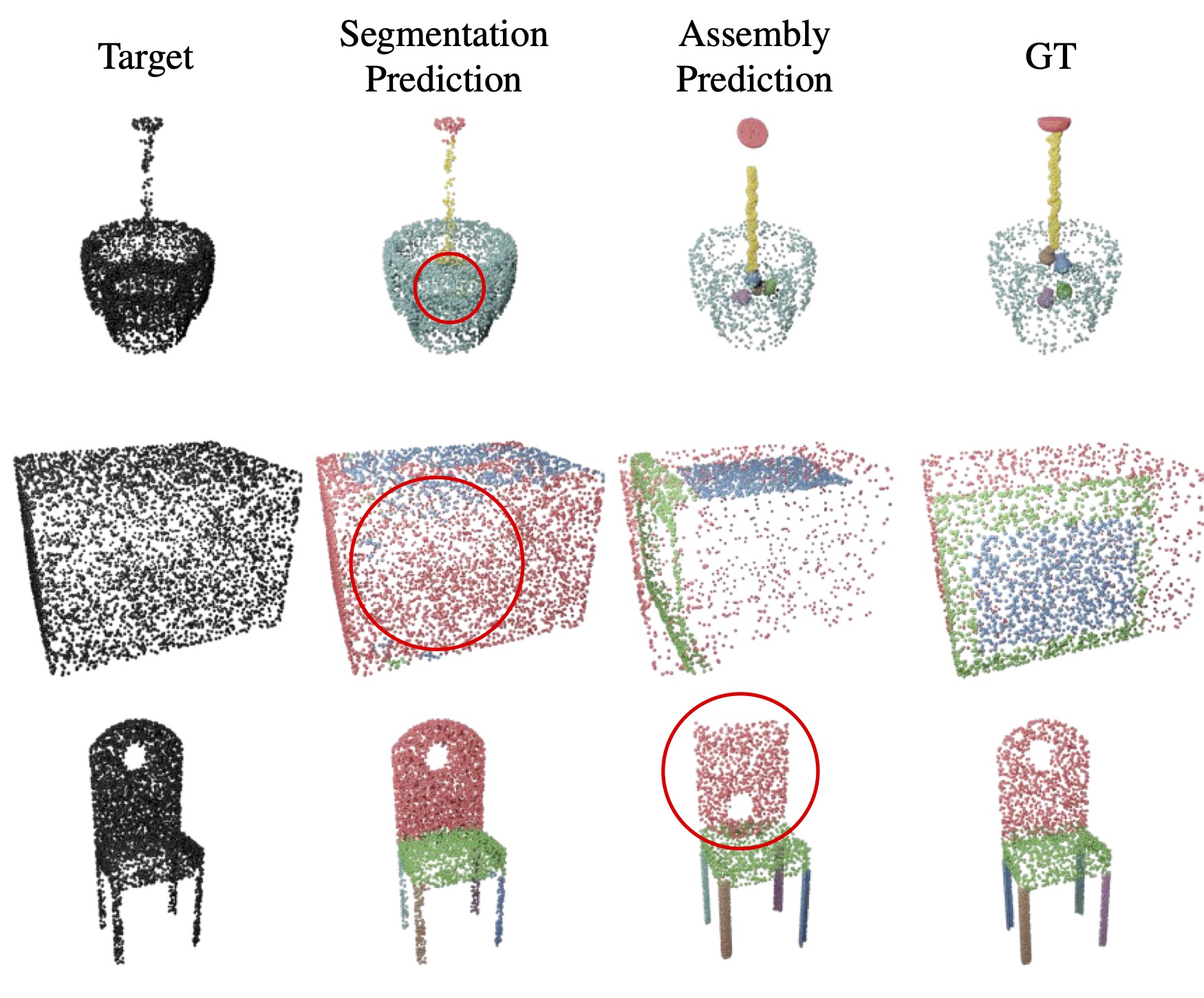
Acknowledgements
We would like to thank Huy Ha, Zhenjia Xu, Cheng Chi, and Zeyi Liu for their helpful feedback and fruitful discussions. This work was supported in part by NSF Award #2037101, #2143601, and #2132519. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.
Citation
To cite this work, please use the following BibTex entry,@inproceedings{li2023rearrangement,
title={Rearrangement Planning for General Part Assembly},
author={Li, Yulong and Zeng, Andy and Song, Shuran},
booktitle={Conference on Robot Learning},
year={2023},
organization={PMLR}
}